背景
当谈起 API 设计时,人们首先会想到 REST API,它是 Representational State Transfer 的缩写。REST API 是标准化的工具,它通过 URL 的方式从服务器上获取数据。
REST 架构的设计范式侧重于分配 HTTP 请求方法(GET、POST、PUT、PATCH、DELETE)和 URL 端点之间的关系。RESTful API 设计指南
1 | GET /api/v1/articles/ |
Rest 使用时的优缺点
优点
-
统一的操作方法,能通过 HTTP 动词非常明确地看出当前是在执行什么操作,例如 POST 表示创建、PUT 表示更新、GET 表示获取资源、DELETE 表示删除资源。不用去自己定义语义化的 url 命名规范了。
-
以资源为对象,能通过 url 一目了然地知道当前操作的对象。/articles 肯定在操作 article,/articles/123/comments 肯定是在操作 id 为 123 的 article 下面的 comments。
-
基于传统 HTTP 协议,学习成本很低,兼容性很高。
不足之处
在使用 REST 接口时,接口返回的数据格式、数据类型都是后端预先定义好的,如果返回的数据格式并不是调用者所期望的,作为前端的我们可以通过以下两种方式来解决问题:
- 和后端沟通,改接口(更改数据源)
- 自己做一些适配工作(处理数据源)
一般如果是个人项目,改后端接口这种事情可以随意搞,但是如果是公司项目,改后端接口往往是一件比较敏感的事情,尤其是对于三端(web、andriod、ios)公用同一套后端接口的情况。大部分情况下,均是按第二种方式来解决问题的。
因此如果接口的返回值,可以通过某种手段,从静态变为动态,即调用者来声明接口返回什么数据,很大程度上可以进一步解耦前后端的关联。
GraphQL 的诞生很大程度上是为了解决这些问题。
GraphqlQL 是什么
官方定义:GraphQL 既是一种用于 API 的查询语言也是一个满足你数据查询的运行时。 GraphQL 对你的 API 中的数据提供了一套易于理解的完整描述,使得客户端能够准确地获得它需要的数据,而且没有任何冗余,也让 API 更容易地随着时间推移而演进,还能用于构建强大的开发者工具。
简单的 graphql 请求示例
描述你的数据
1 | type Project { |
请求你所要的数据
1 | { |
得到可预测的结果
1 | { |
Graphql 核心组成部分

Type
-
对于数据模型的抽象是通过 Type 来描述的,每一个 Type 有若干 Field 组成,每个 Field 又分别指向某个 Type。
-
GraphQL 的 Type 简单可以分为两种,一种叫做 Scalar Type(标量类型),另一种叫做 Object Type(对象类型)。
Scalar Type
-
GraphQL 中内置有一些标量类型 String、Int、Float、Boolean、ID
-
用户也可以定义自己的标量类型,如 Date
-
标量是 GraphQL 类型系统中最小的颗粒
-
枚举类型是一种特殊的标量
示例:
1 | type Article { |
Object Type
-
仅有标量是不够抽象一些复杂的数据模型的,这时候我们需要使用对象类型
-
我们通过对象模型来构建 GraphQL 中关于一个数据模型的形状,同时还可以声明各个模型之间的内在关联(一对多、一对一或多对多)。
示例:
1 | type Article { |
Type Modifier(类型修饰符)
关于类型,还有一个较重要的概念,即类型修饰符,当前的类型修饰符有两种,分别是 List 和 Required,它们的语法分别为 [Type] 和 Type!, 同时这两者可以互相组合,比如 [Type]! 或者 [Type!] 或者 [Type!]!(请仔细看这里!的位置),它们的含义分别为:
- [Type]! 列表本身为必填项,但其内部元素可以为空
- [Type!] 列表本身可以为空,但是其内部元素为必填
- [Type!]! 列表本身和内部元素均为必填
Schema
Schema 使用一个简单的强类型模式语法,称为模式描述语言(Schema Definition Language, SDL)。
它定义了字段的类型、数据的结构,描述了接口获取数据的逻辑,当我们进行一些错误的查询的时候 GraphQL 引擎会负责告诉我们哪里有问题,和详细的错误信息,对开发调试十分友好。
示例:
1 | type Query { |
Query
在 GraphQL 中使用 Query 来抽象数据的查询逻辑。因此,我们可以将 Schema 理解为多个 Query 组成的一张表。
当前标准下,有三种查询类型,分别是
- query(查询):当获取数据时,应当选取 query 类型,对应 CRUD 中的 R
- mutation(更改):当尝试修改数据时,应当使用 mutation 类型,对应 CRUD 中的 CUD
- subscription(订阅):当希望数据更改时,可以进行消息推送,使用 subscription 类型
上面所提及的三种基本查询类型是作为 Root Query(根查询)存在的,对于传统的 CRUD 项目,我们只需要前两种类型就足够了。
对比 Rest 接口与 Graphql Query
- Rest 接口
1 | GET /api/v1/articles/ |
- Graphql Query
1 | query { |
小结:
-
GraphQL 中是按根查询的类型来划分 Query 职能的,同时还会明确的声明每个 Query 所返回的数据类型。
-
需要注意的是,我们所声明的任何 Query 都必须是 Root Query 的子集,这和 GraphQL 内部的运行机制有关。
Resolver(前端如何发起请求)
如果我们仅仅在 Schema 中声明了若干 Query,那么我们只进行了一半的工作,因为我们并没有提供相关 Query 所返回数据的逻辑。为了能够使 GraphQL 正常工作,我们还需要再了解一个核心概念,Resolver(解析函数)。
GraphQL 中,我们会有这样一个约定,Query 和与之对应的 Resolver 是同名的,这样在 GraphQL 才能把它们对应起来,举个例子,比如关于 articles(): [Article!]! 这个 Query, 它的 Resolver 的名字必然叫做 articles。
Graphql 执行机制
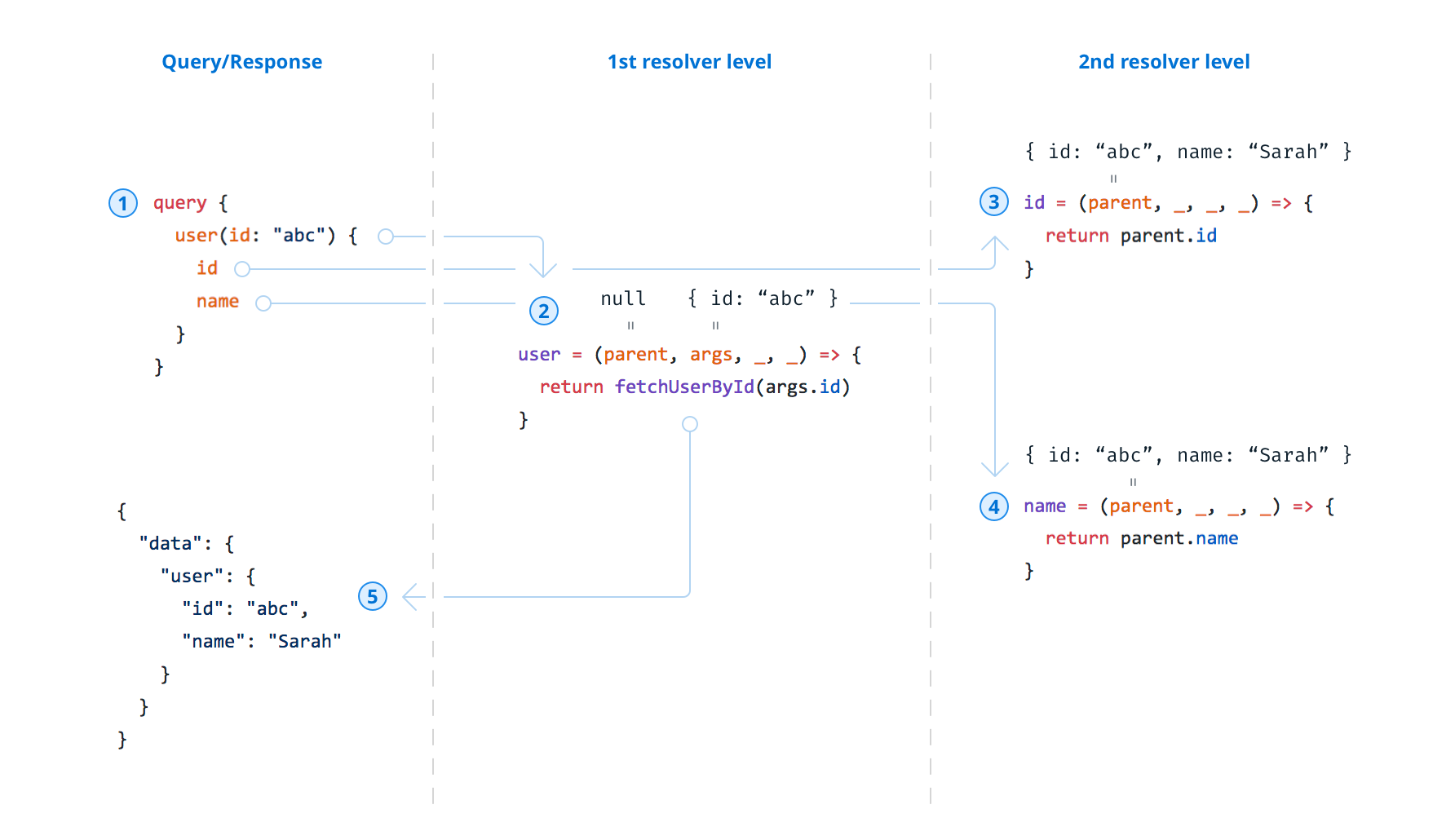
我们可以发现,GraphQL 大体的解析流程就是遇到一个 Query 之后,尝试使用它的 Resolver 取值,之后再对返回值进行解析,这个过程是递归的,直到所解析 Field 的类型是 Scalar Type(标量类型)为止。解析的整个过程我们可以把它想象成一个很长的 Resolver Chain(解析链)。
这里对于 GraphQL 的解析过程只是很简单的概括,其内部运行机制远比这个复杂,当然这些对于使用者是黑盒的,我们只需要大概了解它的过程即可。
Resolver 函数参数
1 | function(parent, args, ctx, info) { |
- parent: 上一级对象,如果字段属于根节点查询类型通常不会被使用。
- args: 传入某个 Query 中的参数(比如 user(id: ID!): User 中的 id)
- ctx: 在 Resolver 解析链中不断传递的中间变量(类似 koa 中的 ctx 上下文)
- info: 一个保存与当前查询相关的字段特定信息以及 schema 详细信息的值
值得注意的是,Resolver 内部实现对于 GraphQL 完全是黑盒状态。这意味着 Resolver 如何返回数据、返回什么样的数据、从哪返回数据,完全取决于 Resolver 本身。
基于这一点,在实际中,很多人往往把 GraphQL 作为一个中间层来使用,数据的获取通过 Resolver 来封装,内部数据获取的实现可能基于 RPC、REST、WS、SQL 等多种不同的方式。
Graphql 基础知识总结
-
Query 代表的是查询的统称,也就是一次查询可以称为一个 Query,而 query 是 Query 的一个类型种类,当前有三种类型,分别是 query(查询),mutation(变更),subscription(订阅)
-
四者关系简单讲是这样的,Schema 由 Type 来描述,Query 的查询语法和格式受 Schema 约束,而 query,mutation,subscription 是 Query 的三种类型,分别对应不同的业务场景,Resolver 则是返回 Query 查询的数据
其他一些复杂应用
- 指令
- 自定义标量
- 别名
- 片段
- 联合类型
- 输入类型
- …
GraphQL 的实际应用
RESTful-Like 模式
这个模式就是简单粗暴的把 RESTful API 服务,替换成 GraphQL 实现。之前有多少 RESTful 服务,重构后就有多少 GraphQL 服务。它是一个简单的一对一关系。
默认情况下,面向两个 GraphQL 服务发起的查询是两次请求,而不是一次。举个例子:
前端需要产品数据时,从之前调用产品相关的 RESTful API,变成查询产品相关的 GraphQL。不过,需要订单相关的数据时,可能要查询另一个 GraphQL 服务。
有一些公司拿 GraphQL 小试牛刀时,采取了这个做法;将 GraphQL 用在特定服务里。
不过,这种模式难以发挥 GraphQL 合并请求和关联请求的能力。只是起到了按需查询,精确查询字段的作用,价值有限。
因此,他们在实践后,发现收效甚微;认为 GraphQL 不过如此,还不如 RESTful API 架构简单和成熟。
其实这是一种选型上的失误。
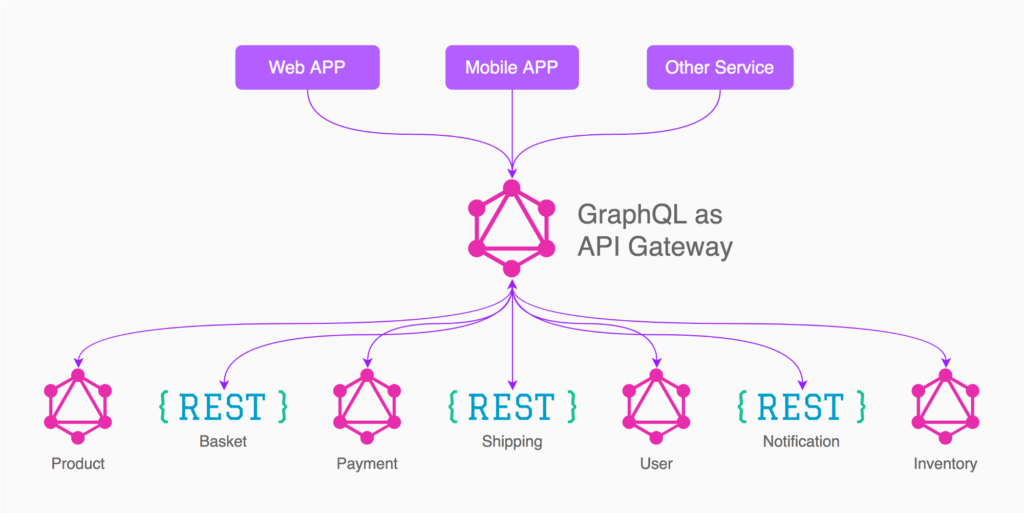
GraphQL as an API Gateway 模式
在这个模式里,GraphQL 接管了前端的一整块数据查询需求。

前端不再直接调用具体的 RESTful 等接口,而是通过 GraphQL 去间接获取产品、订单、搜索等数据。
在 GraphQL 这个中间层里,我们将各个微服务,按照它们的数据关联,整合成一个基于 GraphQL Schema 的数据关系网络。前端可以通过 GraphQL 查询语句,同时发起对多个微服务的数据的获取、筛选、裁剪等行为。
值得一提的是,作为 API Gateway 的 GraphQL 服务,可以在其 Resolver 内,向前面提到的 RESTful-like 的 GraphQL 发起查询请求。
如此,既避免了前端需要一对多的问题,也解决了 API Gateway GraphQL 需要请求 RESTful 全量数据接口的内部冗余问题。让服务到服务之间的数据调用,也可以做到更精确。
GraphQL 服务是一个对数据消费方友好的模式。而数据消费方,既可以是前端,也可以是其它服务。
当数据消费方是其它服务时,通过 GraphQL 查询语句,彼此之间可以更精确获取数据,避免冗余的数据传输和接口调用。
当数据消费方是前端时,由于前端需要跟多个数据提供方打交道,如果每个数据提供方都是单独的 GraphQL,那并不能得到本质上的改善。此时若有一个 Gateway 角色的 GraphQL,可以真正减少前端调用的复杂度。
同样是 API Gateway 角色的 GraphQL 服务,在实现方式上也有不同的分类。
1)包含大量真实的数据操作和处理的 GraphQL
2)转发数据请求,聚合数据结果的 GraphQL
第一类,是传统意义上的后端服务;第二类,则是 GraphQL as BFF(Backend for Frontend)。
这两类 GraphQL 服务的要求是不同的,前者可能包含大量 CPU 密集的计算,而后者总体而言主要是 Network I/O 相关的行为。
并不提倡使用 Node.js 构建第一种服务,不管是构建 RESTful 还是 GraphQL。
GraphQL as a Backend Framework
GraphQL 可以不作为 Server。
这意味着,一个包含 GraphQL 实现的 Server,不一定通过 GraphQL 查询语句进行前后端数据交互,它可以继续沿用 RESTful API 风格。
也就是说,我们可以把 GraphQL 当作一个服务端开发框架,然后在 RESTful 的各个接口里,发起 graphql 查询。
不管是前端还是其它后端服务,都不必知道 GraphQL 的存在。前端的调用方式,还是 RESTful API,在 RESTful 服务内部,它自己向自己发起了 GraphQL 查询。
那么,这个模式有什么好处跟价值?
设想一下,你用 RESTful API 风格实现 BFF。由于 PC 端和移动端的场景不同,它们对同一份数据的消费方式差异很大。
在 PC 端,它可以一次请求全量数据。
在移动端,因为它屏幕小,它要分多次去请求数据。首屏一次,非首屏一次,滚动按需加载 N 次,多个 2 级页面里 M 次。
我们要么实现一个超级接口,根据请求参数适配不同场景(即实现一个半吊子的 GraphQL);要么实现多个功能相似,但又不同的 RESTful 接口。
其中的差异太大了,所以很多公司索性就把 BFF 分成,PC-BFF 和 Mobile-BFF 两个 BFF 服务。
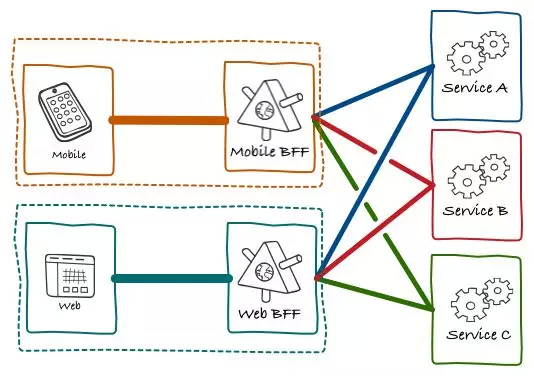
我们可以把 PC-BFF 和 Mobile-BFF 整合成一个 GraphQL-BFF 服务。即便前后端不通过 GraphQL 查询语句进行交互,我们也可以在各个接口里,编写相对简单的查询语句,代替更高成本的接口实现。
也即是说,使用 GraphQL 搭建 BFF,如果出现前后端分工、沟通等方面的矛盾。我们可以将 GraphQL 服务降级为 RESTful 服务,无非就是把需要前端编写的查询语句,写死在后端接口里面罢了。
如果实现的是 RESTful 服务,要转换成 GraphQL 服务,就没有那么简单了。
Graphql 优缺点
优点
-
与多系统和微服务能较好匹配。
GraphQL 将多个系统集成到 API 中,从而形成了统一的 API 接口,并且能够将各个系统的复杂性隐藏在 API 背后。GraphQL 服务器的任务就是从当前这些系统中获取数据,并且将数据打包放入 GraphQL 返回的数据格式中。 -
通过单一的 API 调用获取信息
如果使用 REST API,那么开发者需要把多个接入点合并起来才能收集到所有需要的数据,因为 REST 散落分布在多个独立的接入点上。
GraphQL 与 REST 的主要区别就在这里。开发者仅仅通过一个 API 调用就可以请求到所需信息,而 GraphQL 会专注于主体任务。 -
数据无冗余
按需返回数据,在网络性能上确实有一定优化。 -
根据你的需求自定义请求格式
开发者按照 REST API 文档描述发出请求时,只能请求一些特定的接入点、相关函数和参数等。
而另一方面,GraphQL 可以描述数据类型、字段以及它们之间的任何交互连接点。这就允许 GraphQL 开发者自定义请求格式来获取必要的信息。 -
文档化:GraphQL 的内省功能可以根据 Schema 生成实时更新的 API 文档,且没有维护成本,对于调用方直观且准确。
-
数据 Mock:服务端 Schema 中包含数据结构和类型,所以在此基础上实现一个 Mock 服务并不困难,apollo-server 就有实现,可以加快前端开发介入。
-
版本控制:客户端结构化的查询方式可以让服务追踪到字段的使用情况。且在增加字段时,根据结构化查询按需查询的特点,不会影响旧的调用(虽然 JavaScript 对多了个字段的事情不在意)。对于服务的迭代维护有一定便利。(如果接口是大改或是重构,这种情况是用不到 Graphql 的版本控制优势的)
缺点
- GraphQL 为何没有火起来
- N + 1 问题(官方解决方案:dataLoader)
- 开发成本:毫无疑问 Resolver(业务行为)的开发在哪种服务模式下都不可缺少,而 Schema 的定义一定是额外的开发成本,且主观感受是 Schema 的开发过程还是比较耗费精力的,数据结构复杂的情况下更为如此。同时考虑到开发人员的能力差异,GraphQL 的使用也会是团队长期的人员成本。
- 调用合并:GraphQL 的理念就是将多个查询合并,对应服务端,通常只会提供一个合并后的“大”的接口,那么原本以 URL 为粒度的性能监控、请求追踪就会有问题,可能需要改为以 root field(根字段)为粒度。这也是需要额外考虑的。
总结
- GraphQL 并不是要完全取代 REST,因为前者只是一个工具,而 REST 是一种架构模式。具体哪一个更合适,将取决于它们独特的交互场景,亦可以共存。
- 综合来看,可用的 GraphQL 服务(不考虑拿 GraphQL 做本地数据管理的情况)的重心在服务提供方。作为 GraphQL 的调用方是很爽的,且几乎没有弊端。那么要不要使用 GraphQL 就要重点衡量服务端的成本收益了。
最后:
GraphQL exists because JavaScript developers finally realized HTTP API’s were too limiting so they reinvented SQL over JSON because JavaScript developers are obsessed with reinventing everything into JSON API’s。 ——@kellabyte
GraphQL 的本质是程序员想对 JSON 使用 SQL。 —— 来自阮一峰的翻译